Reflecting on the Open Source Business Model
A long history
After having spent more than a decade using and building my career around free and open source software, I feel compelled to reflect on the choices I made, the lessons I learned, and the knowledge I gained along the way. Reflection doesn’t necessarily imply regret. Rather, time has a way of revealing trade-offs that enthusiasm and passion tend to gloss over.
I don’t clearly remember how I was first introduced to free software, but I do remember why it appealed to me. Growing up in a developing country, access to required software was either prohibitively expensive or casually copied from one user to another—how the prior user obtained it, or whether the copy was even usable, was often left to the imagination. Free software offered something rare: access without compromise. It provided a full-fledged, working version (assuming you could make it work) and access without guilt. The license explicitly permitted free and fair use. I could learn, experiment, and build without the lingering anxiety of a pop-up accusing me of using software without permission.
The cost, of course, was time.
I still remember the first time I decided to install Linux on a newly acquired desktop. Legacy shared interrupt conflicts—between the sound card and another device—prevented the kernel from booting. This was evident from the loud, noisy kernel boot log, something anyone coming from Windows would have found alien. The problem disappeared if I disabled sound in the BIOS. Discovering that workaround, however, took days of debugging. Yet the initial feeling of helplessness gradually gave way to something else: empowerment. With free software, there was usually a way forward, even if it wasn’t obvious at first.
Nerd
Through school and early academic work, I often felt like the odd one out. I gravitated toward kernel internals, memory management, and free software, while most of my peers focused on object-oriented design, design patterns, or computer vision. This gap was exacerbated by the lack of mentors in these areas—until graduate school, there were few experts I could turn to for guidance. Peers, and sometimes even advisors, weren’t quite sure what to do with those interests, and there was always a subtle nudge to “wake up” and align with more mainstream stacks and career paths.
I ignored most of it. My peers laughed.
By the time I reached graduate school, my interest was no longer limited to code and usability. The free software movement, the open source model, and the philosophy surrounding them had become equally compelling. I understood that just because free software benefits society does not mean it can sustain a business. That is where the open source business model steps in. History has shown that companies can build profitable models around open source, but they cannot survive by selling freedom alone. This distinction would later prove far more important than I initially imagined.
I made compromises where they aligned with my broader goals—working at product companies that developed Linux drivers, taking internship opportunities adjacent to my interests because they offered access to teams I aspired to join, and so on. I was determined not to lose focus. Systems-level work, upstream communities, patches and reviews, and environments that valued technical clarity over hierarchy remained my priorities.
The view from the inside
For like-minded people, open source work can be intoxicating. It feels expansive. It allows collaboration beyond immediate teams, contributions to projects an employer may not own, and the opportunity to build an identity tied to patches, reviews, and technical discussions rather than titles. The reward is recognition and a deep sense of participation.
Open source communities are also naturally inclusive. Academia fits easily into this model, as do independent contributors and paid engineers from industry. I leaned into this fully. Some of the most rewarding work I have done lived at the intersection of industry and academic research—projects that were technically meaningful even if they never became products.
The open source company
An open-source-centric company may appear exotic from the outside, but internally it faces the same pressures as any other business. Revenue matters. Survival matters. While the mission may be broader and amplified through branding, it is rarely the highest-priority concern for the business itself.
This creates a quiet tension.
Open source makes intellectual success more accessible. It is not bound by a single company, region, or domain. It allows engineers to build reputation, influence direction, and operate at a level of technical depth that many proprietary environments do not. Career progression, however, follows a different logic. Achievement is tied less to what one enables for the ecosystem and more to how directly one’s work maps to customer acquisition, retention, or revenue protection.
That mapping is often indirect. An engineer may work on or maintain a critical subsystem used widely across the industry, yet find that its impact is diffuse rather than attributable. In organizations whose primary business is support, subscriptions, or services layered on top of shared infrastructure, this makes it difficult to translate community contributions and leadership into internal leverage. This is not universal, and it may not apply to everyone. It is also not malicious. It is structural. Evaluation systems are designed around business outcomes, not communal value creation. Over time, priorities drift—not because people stop caring about open source, but because incentives quietly reshape what is rewarded.
The big trade-off
This is the hardest realization I have come to.
In most technology companies, engineers are treated as high-leverage assets: they own proprietary systems, accumulate tacit knowledge, and maintain code that directly anchors revenue. In many open-source-centric business models, this relationship does not hold in the same way—not because an engineer’s work is less important, but because ownership and scarcity are distributed by design.
Open source excels at eliminating single points of failure. Knowledge becomes visible. Expertise becomes shared. This produces enormous societal benefit, but it also means that individual contributors are rarely irreplaceable in the economic sense. As a result, revenue per engineer often tends to be lower than in proprietary or product-centric companies—not because revenue does not exist, but because it is only weakly coupled to marginal technical excellence. This can affect compensation, recognition, and even self-perception. It is difficult to acknowledge, even implicitly, that work benefiting millions does not clearly move the business needle.
This is not a post proposing solutions. The outcome is largely by design. It is not a failure of leadership or ethics, but the natural consequence of a model optimized for collective resilience rather than individual leverage.
Choice
None of this diminishes the value of open source. It remains one of the most effective mechanisms we have for learning, collaboration, and durable technical progress. It is an unmatched tool for intellectual growth and professional credibility.
But it is not a neutral career choice.
Open source amplifies opportunity, not ownership. Engineers who prioritize learning, autonomy, and community impact have much to gain from it. For those optimizing for financial upside, indispensability, or tightly coupled value creation, it may fall short unless paired with proprietary leverage—products, platforms, or distribution.
I do not view my own path as a mistake, but as a trade-off I accepted without fully understanding its long-term implications. Understanding that trade-off does not make open source less meaningful. It makes participation a conscious choice rather than an assumed good.
That, at least, is the model I wish I had understood earlier in my career.
Further reading:
– Y. Benkler, The Wealth of Networks
– E. S. Raymond, The Cathedral and the Bazaar
– S. Wardley, Wardley Mapping
– N. Ravikant, essays and talks on leverage and ownership
– Linux Foundation, Open Source Sustainability Reports

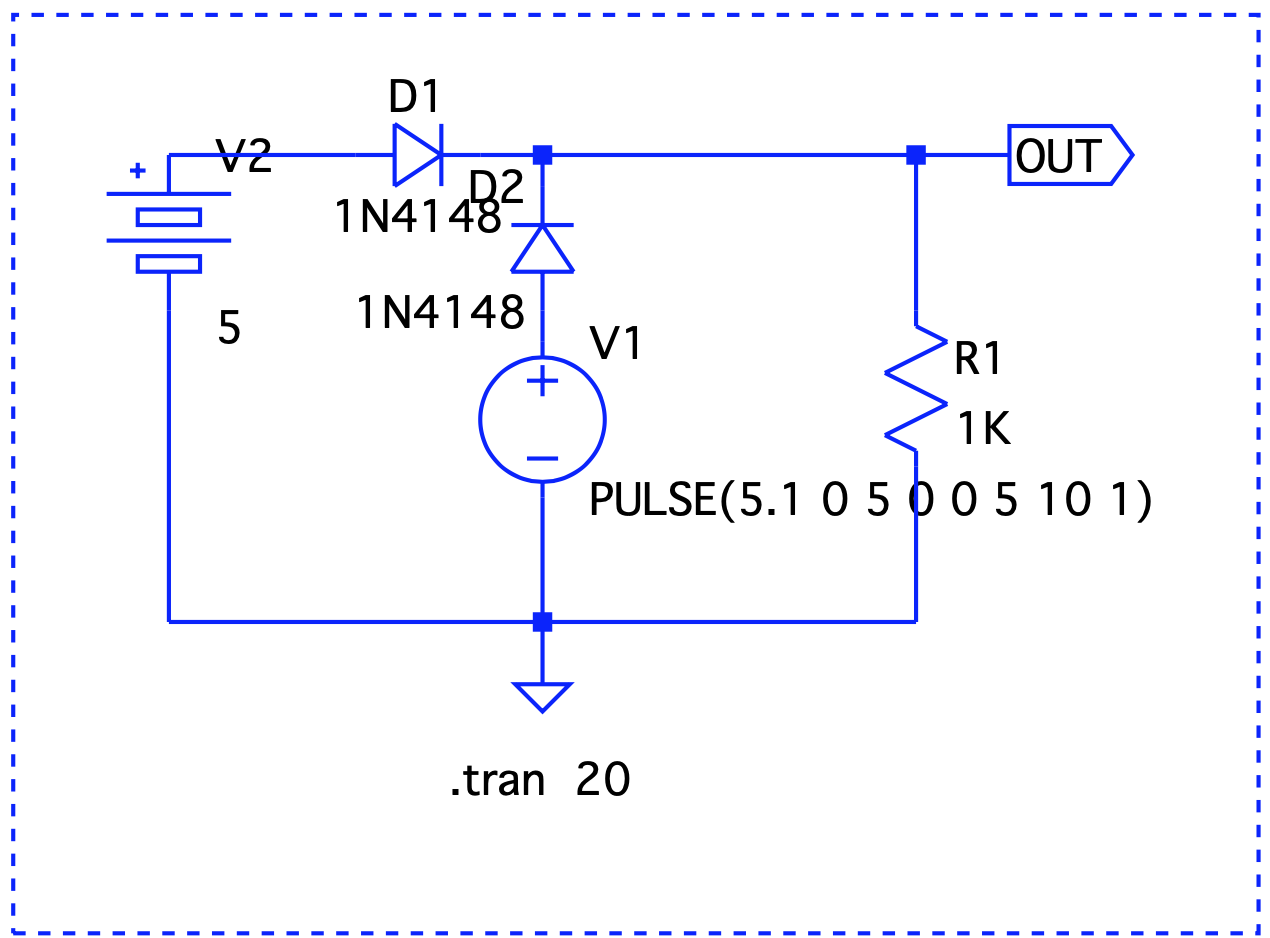
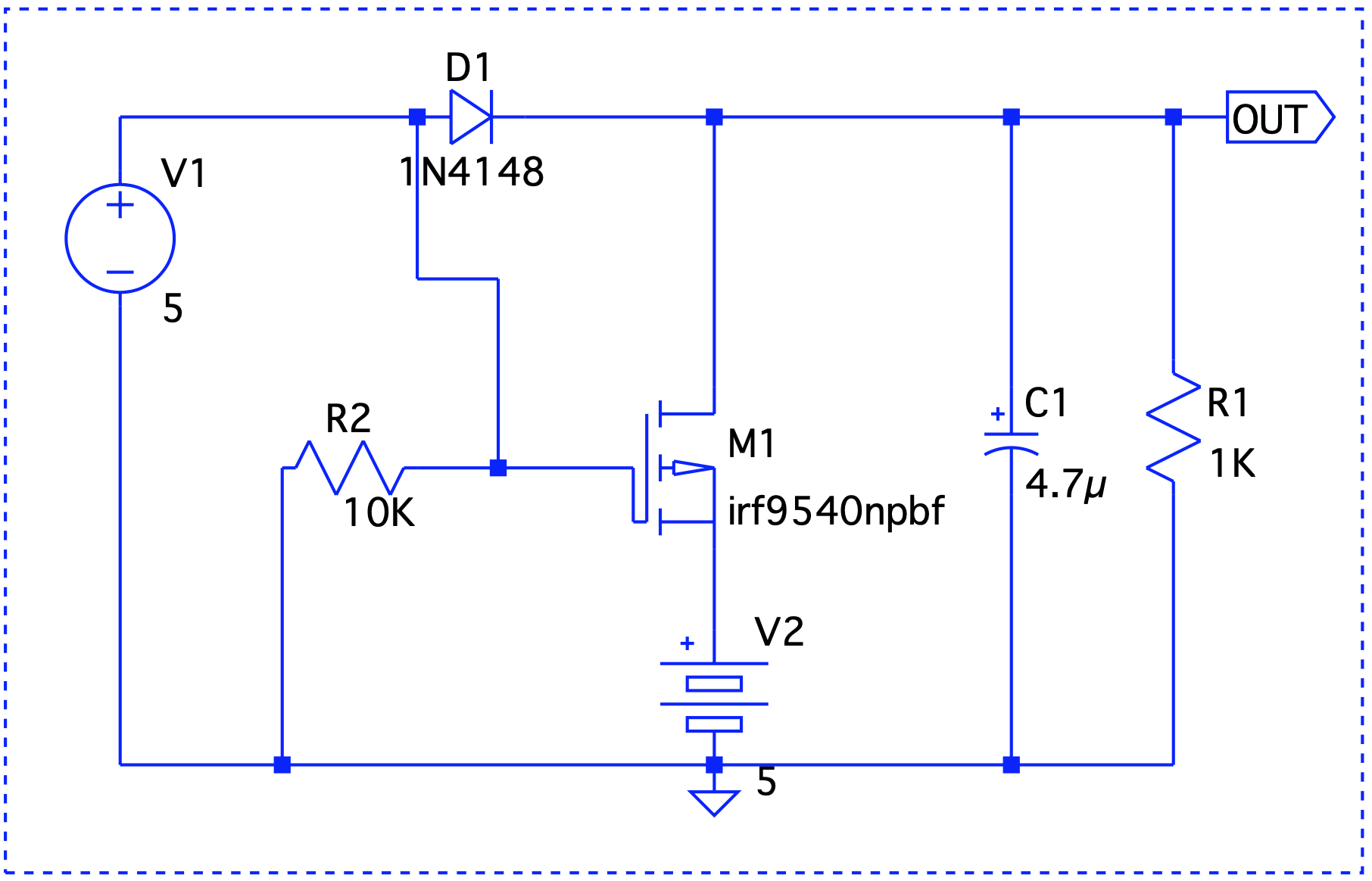

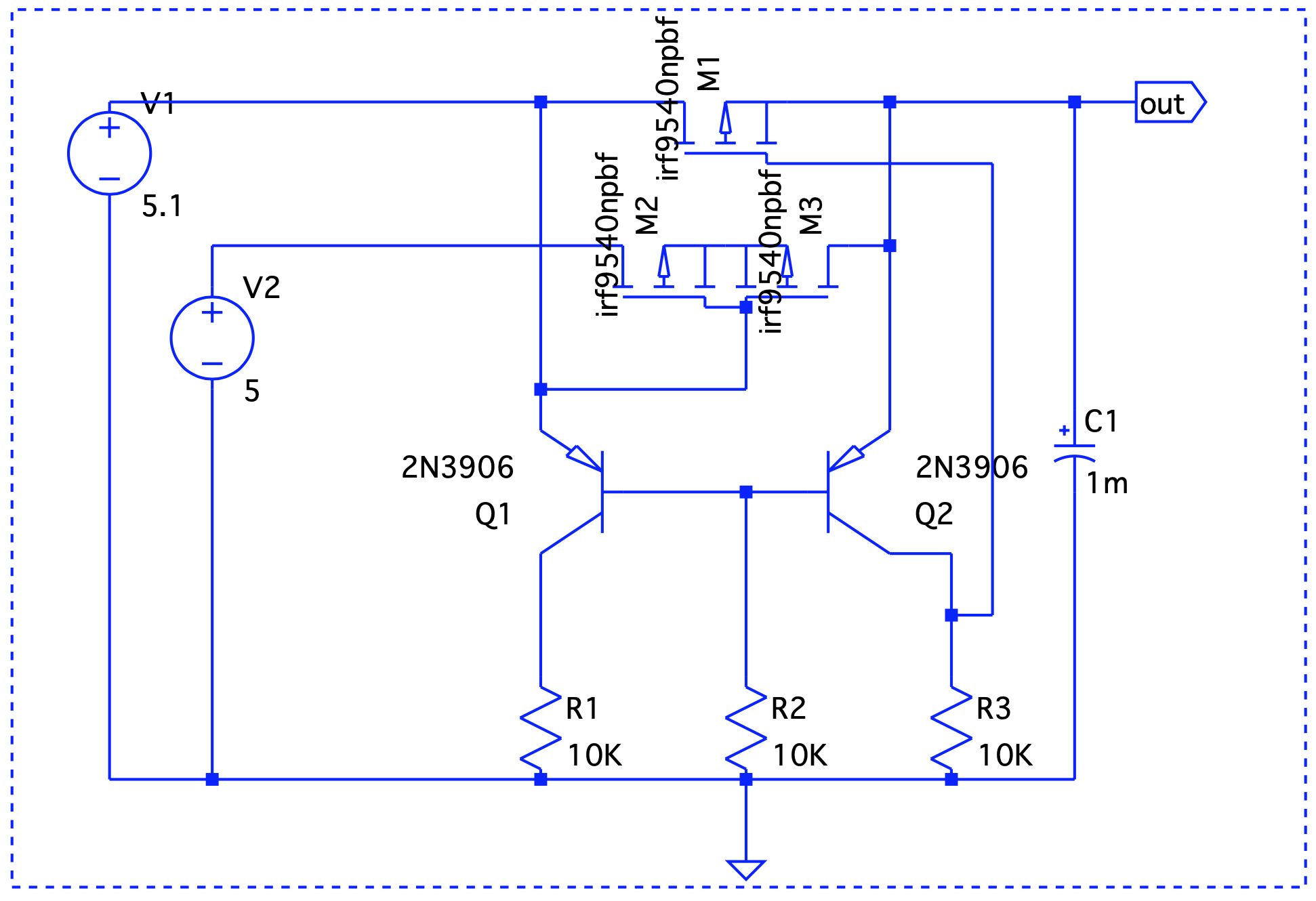
 Here, Vout is V1 – the forward voltage drop, so we are good.
Here, Vout is V1 – the forward voltage drop, so we are good. Even though V1 < V2, it still takes precedence.
Even though V1 < V2, it still takes precedence. When V1 is on, it drives the output. V2 takes over at t=2 and until t=6.
When V1 is on, it drives the output. V2 takes over at t=2 and until t=6.
