Backup VPN tunnel using a MVNO data plan
Problem Statement
I wanted a cheap backup VPN tunnel to reinforce my main tunnel in case things go wrong. The backup tunnel is on standby and is utilized only when I need an alternate path to investigate why my main network is down or isn't functioning when I am physically away from my systems.
Challenges
CG-NAT has ruined cellular network based data plans. Cellular networks have kept their eccentric design choices throughout their evolution even though they have leveraged a lot from regular internet based data networks. CG-NAT is one of those inconvenient design choices that has stayed on. To summarize, a lot of the cheap MVNO data plans operate like a NATed LAN and incoming connections aren't really possible because you do not get gifted with a public IP. Setting up a VPN tunnel using one of these data networks becomes a bendy road to success.
Design choices
Using a cheap data plan is quite appealing because I would ideally want the cost to be as low as possible without sacrificing much on the minimum reliability that you would expect from a backup network.
Owing to the design restrictions mentioned above, you cannot simply dial in to your backup VPN endpoint. The connection has to be initiated in the opposite direction. This post details how I achieved an usable setup without sacrificing too much on cost or reliability.
Network topology

Click here for a somewhat legible image.
Main LAN (1)
The main network gated by a OpenBSD based firewall and gateway.
BMC (2)
The base management controller to control the gateway.
CRS 326 (3)
This is the backup gateway using a Mikrotik CRS326. It's probably overkill for what I am trying to achieve. It provides three different functions in our setup:
Backup firewall/gateway
Creates another smaller LAN composed of BMCs for systems that provide services. This LAN is also accessible from the main LAN. This is simple using masquerade rules.
On Mikrotik:
chain=srcnat action=masquerade out-interface=<backuplanbridge> log=yes log-prefix="BackupLANBridge>"
Note that, for this to work, one of the interfaces of backup gateway's bridged network should be a dhcp client on the main LAN.
The backup firewall is connected to the internet via the LM1200 (4).
Scheduler
We also use the scheduler function of the Mikrotik box. It checks a cookie at regular intervals in case user has requested VPN to be on. While you have a always-on tunnel, I would like to minimize data usage on the data only SIM (the backup network).
A simple script to check a variable on remote web server(RouterOS):
# Check if user has enabled cookie
:local result [/tool fetch url="<path to remote web server>/radar.txt" mode=https as-value output=user ]
:delay 5
:local dat ($result->"data")
:log info ("Wireguard, Cookie is:$dat")
# check if user wants to run tunnel
:if ( [: pick $dat 0 1] != "0") do={
:local status [/interface get <wireguard interface> disabled];
:if ($status=true) do={
:log info "Trying to enable wireguard interface";
/interface/wireguard/enable <wireguard interface>;
:delay 5;
} else={
:log info "Wireguard interface already enabled";
}
# For debugging
/ping count=5 10.8.0.1;
} else={
:log info "Trying to disable wireguard interface";
/interface/wireguard/disable <wireguard interface>;
}
To set this to run every 5 minutes:
add disabled=no interval=5m name=<myscript>
Wireguard endpoint
This is the configured interface we have referred above in the script.
LM1200 (4)
This is most convenient device I could find for my needs. It takes in a data sim and gives you a bridged interface.
CG-NAT (5)
The cellular network.
AWS S3 Cookie (6)
I use a publicly accessible S3 bucket for my cookie. All it needs is writing a 0 or 1 to a text file.
Wireguard Server (7)
This is another critical piece of the setup. It serves as a bridge between the roaming endpoint and the local site. Besides the necessary firewall rules, some masquerade and postrouting rules are required:
iptables -t nat -I POSTROUTING -o eth0 -j MASQUERADE
iptables -t mangle -A POSTROUTING -p tcp --tcp-flags SYN,RST SYN -o wg0 -j TCPMSS --set-mss 1280
The mangle is essential since we are accessing the tunnel indirectly via another system. Note that instead of setting a —set-mss value explicitly, you can just use —clamp-mss-to-pmtu that automatically sets an appropriate value.
Roaming system configuration
Before we get to our script that makes life a bit easier, here's the typical workflow:
- User detects that the main network is down and primary VPN does not work.
- User sets cookie in the S3 bucket to 1.
- User waits for the remote backup system to initiate a wireguard tunnel.
- Once done, user uses a ssh tunnel or a wireguard tunnel to the wireguard server.
Here's a script that does something similar.
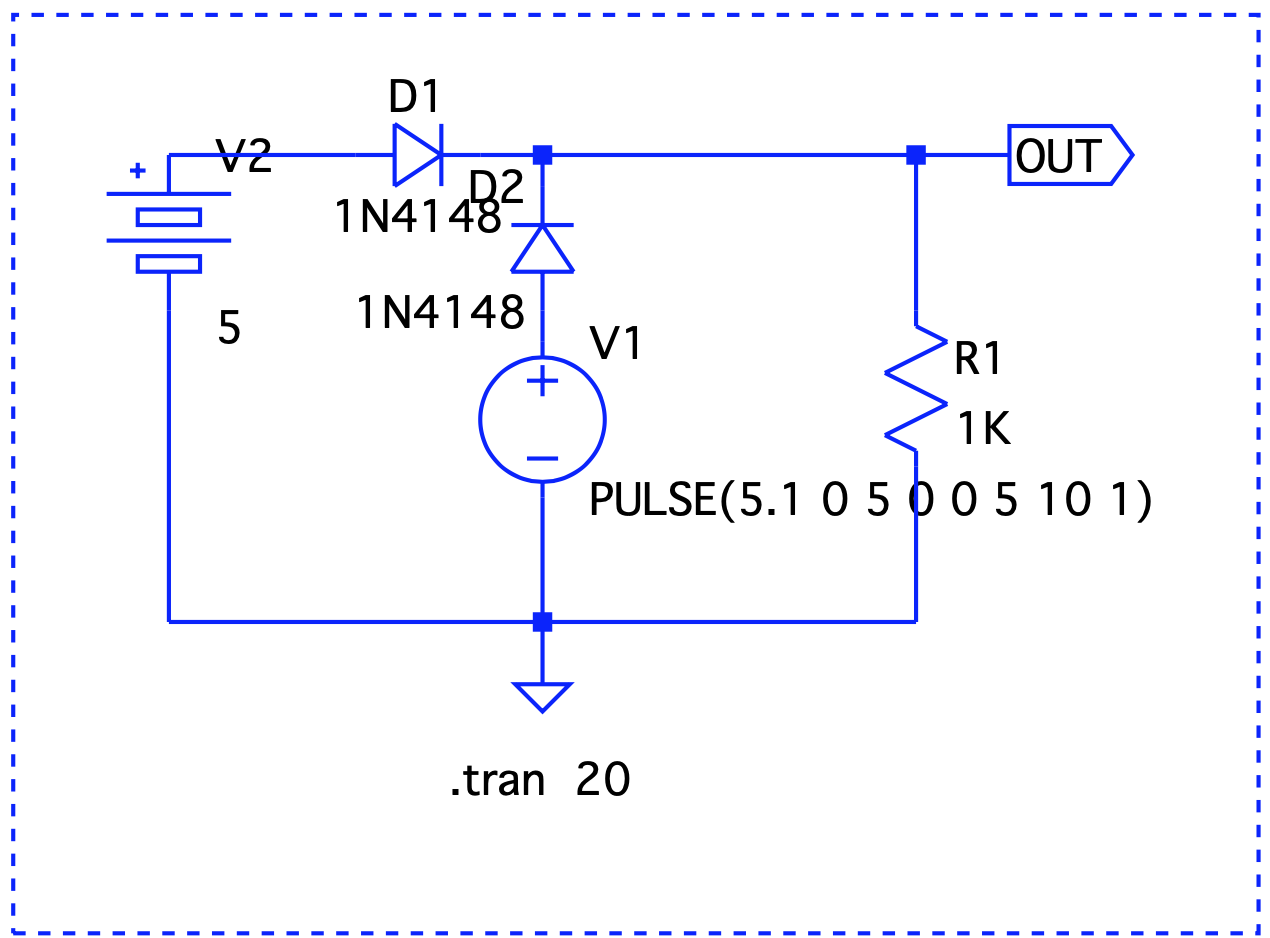
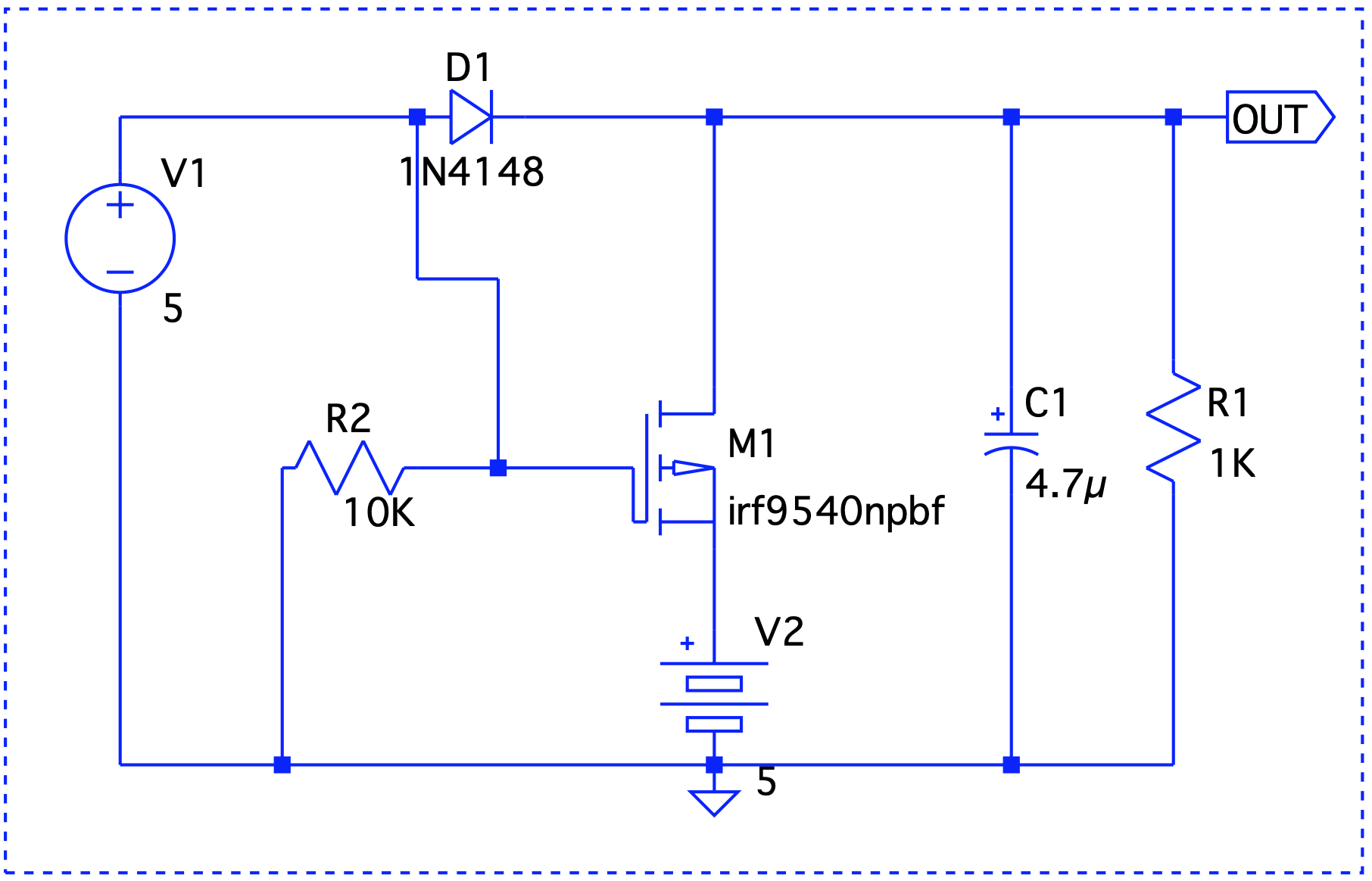

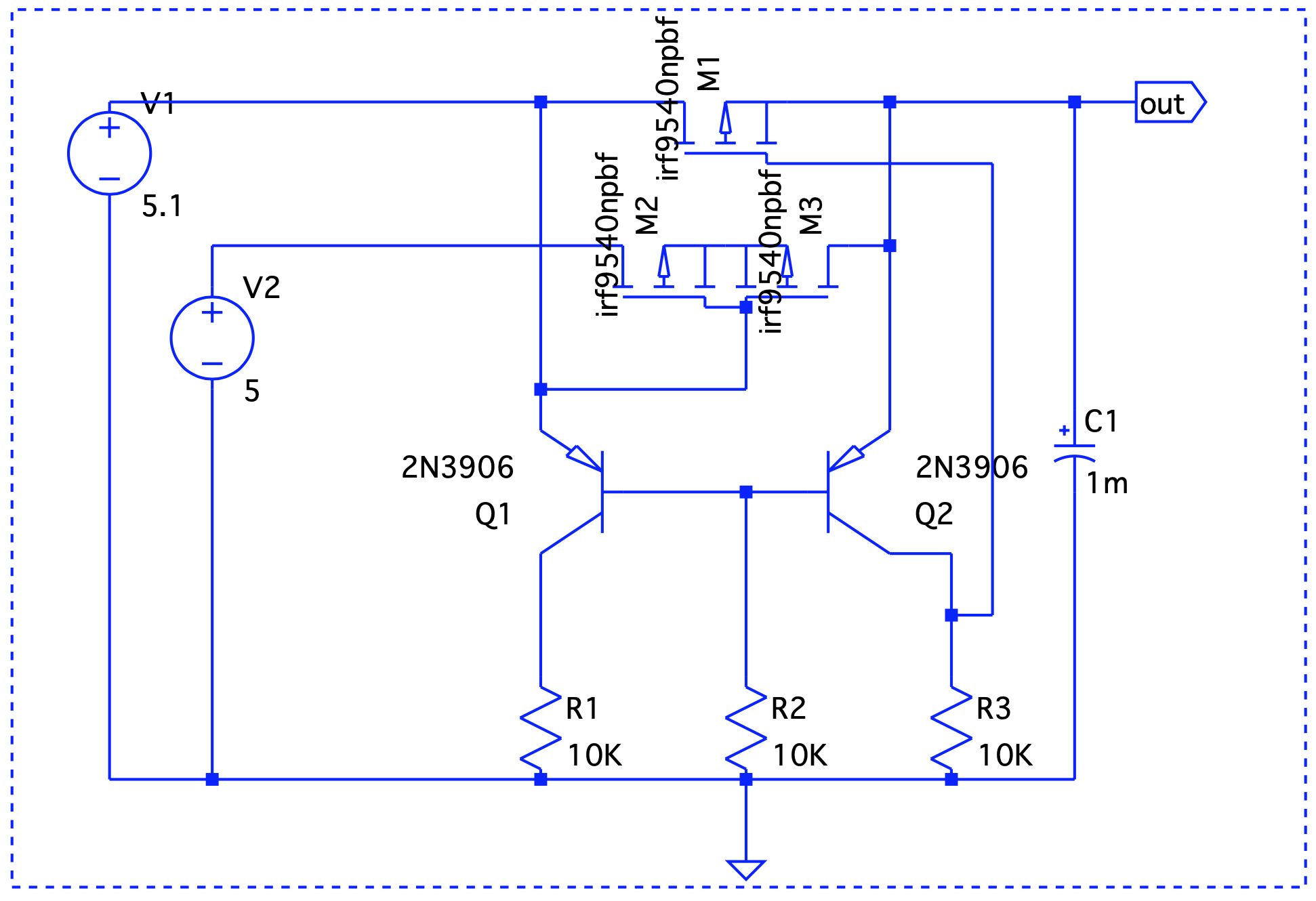
 Here, Vout is V1 – the forward voltage drop, so we are good.
Here, Vout is V1 – the forward voltage drop, so we are good. Even though V1 < V2, it still takes precedence.
Even though V1 < V2, it still takes precedence. When V1 is on, it drives the output. V2 takes over at t=2 and until t=6.
When V1 is on, it drives the output. V2 takes over at t=2 and until t=6.
